

The butterfly effect has become a popular concept, having originated in the work of mathematician and meteorologist Edward Norton Lorenz. In his weather models, he noticed that the specific details of a tornado, such as the time of formation or the path taken, were being influenced by minor perturbations such as a distant butterfly flapping its wings several weeks earlier. More popularly it just expresses the idea that small, apparently trivial events may ultimately result in something with much larger consequences.
And indeed, the presentation of an obscure paper on a new architecture for sequence transduction models in 2017 at the 31st Conference on Neural Information Processing Systems in Long Beach, California, by a group of researchers from the Google Brain team could not have seemed more underwhelming.
They called it the “Transformer” model—possibly inspired by their favourite teen action movie. In any case, it seemed no one took much notice at the time, and certainly Alphabet itself must not have thought much of it, given that it allowed the team to release its new architecture design and specifications for free to the wider research community.
Yet the flapping of that butterfly in 2017 in Long Beach caused a few waves, initially barely noticeable, but by November 2022 a start-up called OpenAI, which took good notice of the Transformer potential, shocked the world with the release of its conversational ChatGPT AI platform, unleashing the ‘generative AI tornado’.
Why did the generative AI ‘butterfly’ emerge in late 2022?
Let’s go back to the fundamentals of generative AI to understand why the Transformer model became the trigger of the generative frenzy, even if it took a few years to manifest itself.
Current state-of-the-art generative AI revolves around the use of a type of neural network called large language models (LLMs). Inspired by the structure of the brain, neural networks are one of the main tools used in machine learning. An artificial neural network has anywhere from dozens to millions of artificial neurons—called units—arranged in a series of layers. The input layer receives various forms of information from the outside world. This is the data that the network aims to process or learn about. From the input unit, the data goes through one or more hidden units to transform the input into something the output unit can use.
How well do you really know your competitors?
Access the most comprehensive Company Profiles on the market, powered by GlobalData. Save hours of research. Gain competitive edge.

Thank you!
Your download email will arrive shortly
Not ready to buy yet? Download a free sample
We are confident about the unique quality of our Company Profiles. However, we want you to make the most beneficial decision for your business, so we offer a free sample that you can download by submitting the below form
By GlobalDataYet up until recently, neural networks were being used to recognize human faces or to detect fraud patterns in financial data, rather than process natural language. Further, neural networks have been around for decades, so why has this explosion in generative AI happened now? Indeed, repentant cognitive psychologist and computer scientist, and former Googler, Geoffrey Hinton, came up with the foundational backpropagation algorithm used by most neural networks back in 1986, however, the butterfly was yet to take flight.
What do we mean by an ‘AI creation’?
Let’s first understand at a high level how these large language models actually ‘create’. AI creation is, in essence, a translation between two languages, which in the industry is called either ‘neural machine translation’ or ‘sequence transduction’.
These models will typically use two connected neural networks: an Encoder network and a Decoder network. The first one encodes the input language into an internal mapping or state. One could think of it as the meaning of words learned by the Encoder after being trained on lots of data samples. The second neural network or Decoder, works in reverse, taking the internal states and learning to map them to the words in the output language.
However, for an LLM, a ‘language’ could be a human language like English, French, or Chinese, or a programming language like Python or Java, as well as images, videos, or protein structures. As such, LLMs are applicable to many scenarios, including translation, conversation, visual generation, and music generation. In the specific case of ChatGPT, rather than learning to map sentences from English to French, it was trained to map English answers to English questions.
Historically, using neural networks to deal with language raised performance challenges, because words needed to be processed one at a time. It is easy to understand by comparing it to another very popular use of neural networks, computer vision. Particularly in the case of facial recognition, the industry was able to progress very rapidly in the last decade. So, what is the difference?
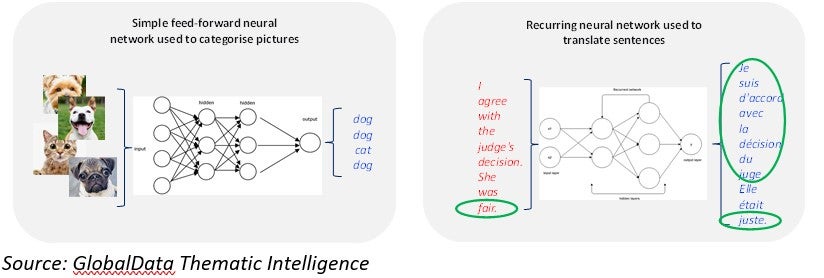
The computer vision network on the left can be trained in parallel because the categorization of the second dog is totally independent of the first one. This allowed for the scaling of those systems with the use of very large data sets and lots of GPUs in a data center.
However, the language translation network on the right shows the complex nature of human language. The French translation of the English word ‘fair’ depends on the prior context. Does ‘fair’ translate to ‘juste’ or ‘blond’? As a result, these neural networks need to be recurring, with the output of earlier word translations feeding into the translation of later words. Further, the relevance of prior words varies. In the above example, the word ‘judge’ is more critical in helping translate ‘fair’ than the words ‘agree’ or ‘with’.
In practical terms, this meant that very large datasets took too long to process as this could not be done as much in parallel as in the computer vision scenarios.
Enter the Transformer
Now, that seemingly humble Transformer algorithm published in 2017, which is based solely on attention mechanisms, dispensing with recurrence and convolutions entirely, effectively solved the key limitations of prior deep learning models for language. First, the lack of parallelism, which made training too slow and expensive. Second, determining which words in the original sentence are more relevant.
The rest is history but combining the parallel Transformer algorithm with increasingly faster AI chips from the likes of NVIDIA and AMD—as well as start-ups such as Graphcore, Groq, and Horizon Robotics—AI practitioners were able to build and train extremely large language models within reasonable timeframes. The quickly aging GPT-3 model has 175 billion parameters.
Whether the butterfly driven ‘generative AI tornado’ will end in catastrophe is anybody’s guess, but it is a vital discussion for another day.





Related Company Profiles
Alphabet Inc
Google LLC
NVIDIA Corp
Horizon Robotics Inc